BigQueryから直接特許データを調べる:ADKの新機能で自然言語クエリを実現
- NISHIO KEI
- 2025年9月2日
- 読了時間: 3分

1.はじめに
従来、Google CloudのBigQueryに格納されている広範な公開特許データセット(Google Patents Public Datasets)を調査するには、SQLの知識が不可欠でした。 [1]しかし、Agent Development Kit (ADK) のアップデートにより、自然言語を使って直接これらのデータに問い合わせることが可能になりました。[2]
本記事では、ADKのask_data_insightsツールを利用して、google patents public datasetに自然言語でクエリを投げ、特許情報を取得する方法を解説します。[1][2]
2.使用する技術とデータセット
Agent Development Kit (ADK): Google製のAIエージェント開発フレームワークです。バージョン1.13.0で追加されたask_data_insightsツールは、BigQueryのConversational Analytics APIを利用して、自然言語によるデータ問い合わせを実現します。 [2]この機能は、大量のデータを扱う際にLLMのコンテキストウィンドウが溢れる問題を回避するのに役立ちます
Google Patents Public Datasets: BigQuery上で公開されている特許データセットで、世界各国の特許書誌事項などが含まれています。 [1]今回はpatents-public-data.patents.publicationsテーブルを対象とします。
3.実装手順
ADKでエージェントを作成
まず、adk createコマンドを使って、エージェントの雛形を作成します。
adk create patent_agentモデルとかGoogleAPIキーなどを設定

agent.pyの編集
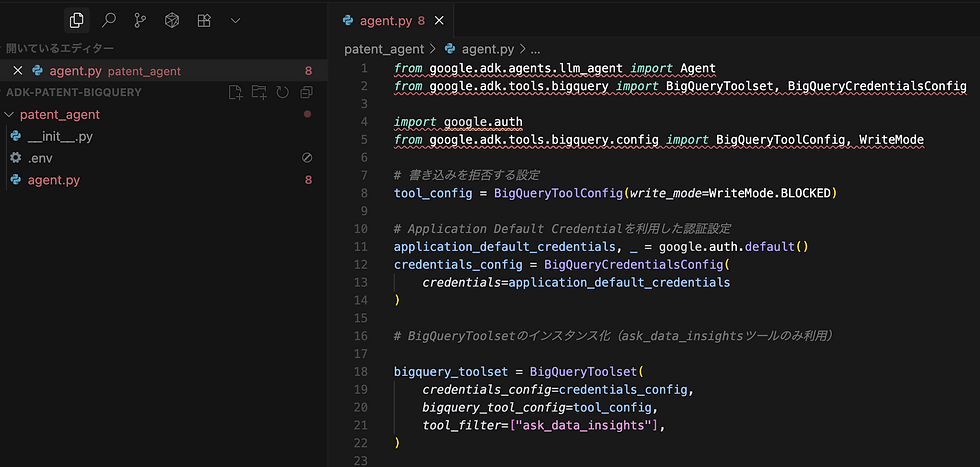
生成されたpatent_agentディレクトリ内のagent.pyを編集し、BigQueryToolsetを設定します。 [2]ここでは、SQL実行ツールを除外し、自然言語クエリ用のask_data_insightsツールのみを利用するようにtool_filterで指定します。
from google.adk.agents.llm_agent import Agent
from google.adk.tools.bigquery import BigQueryToolset, BigQueryCredentialsConfig
import google.auth
from google.adk.tools.bigquery.config import BigQueryToolConfig, WriteMode
# 書き込みを拒否する設定
tool_config = BigQueryToolConfig(write_mode=WriteMode.BLOCKED)
# Application Default Credentialを利用した認証設定
application_default_credentials, _ = google.auth.default()
credentials_config = BigQueryCredentialsConfig(
credentials=application_default_credentials
)
# BigQueryToolsetのインスタンス化(ask_data_insightsツールのみ利用)
bigquery_toolset = BigQueryToolset(
credentials_config=credentials_config,
bigquery_tool_config=tool_config,
tool_filter=["ask_data_insights"]
)
# エージェントの定義
root_agent = Agent(
model='gemini-2.5-flash',
name='root_agent',
description='A helpful assistant for patent data research.',
instruction="""
You are a patent research agent.
You have access to the ask_data_insights tool to query the BigQuery patents-public-data dataset.
Use this tool to answer the user's questions about patent data.
""",
tools=[bigquery_toolset]
)こんな感じでした。
エージェントの起動
ターミナルで以下のコマンドを実行し、Web UIを起動します。
adk web .チャット画面が出てきます!
4.特許データを自然言語で検索する
Web UIが起動したら、チャット画面から特許データに関する質問を自然言語で投げることができます。例えば、以下のようなプロンプトを試してみましょう。
プロンプト例:
「patents-public-data.patents.publications テーブルを利用して、「自動運転」に関連する日本の特許(publication_numberが'JP'で始まるもの)について、出願人(assignee)ごとの特許数を降順でトップ5を教えて。あなたのプロジェクトIDは [YOUR_PROJECT_ID] です。」
下記のAPIを有効にして、と怒られて有効化

できました!

人が指定した自然文から作成した実際のクエリはこんな感じです。ABSTとタイトルを指定して「自動運転」でやっています。英語でもやってほしかったですが、これは指示すれば良さそうです。
いやーすごいですね!読みやすさのために改行するとこんな感じです。
SELECT
t0.name AS assignee_name,
COUNT(DISTINCT t.publication_number) AS count_of_patents
FROM `patents-public-data`.`patents`.`publications` AS t, UNNEST(t.assignee_harmonized) AS t0
WHERE t.country_code = 'JP' AND
(
EXISTS(
SELECT 1 FROM UNNEST(t.title_localized) AS title
WHERE title.text LIKE '%自動運転%' )
OR
EXISTS(
SELECT 1 FROM UNNEST(t.abstract_localized) AS abstract
WHERE abstract.text LIKE '%自動運転%' ))
GROUP BY assignee_name ORDER BY COUNT(DISTINCT t.publication_number) DESC LIMIT 5;BigQueryもSQLっぽいものを書かないといかなかったのですが、これでアナリスト寄りの人もガンガン使えそうです。

[1]Google Patents Public Datasetsについて #BigQuery - Qiita
